
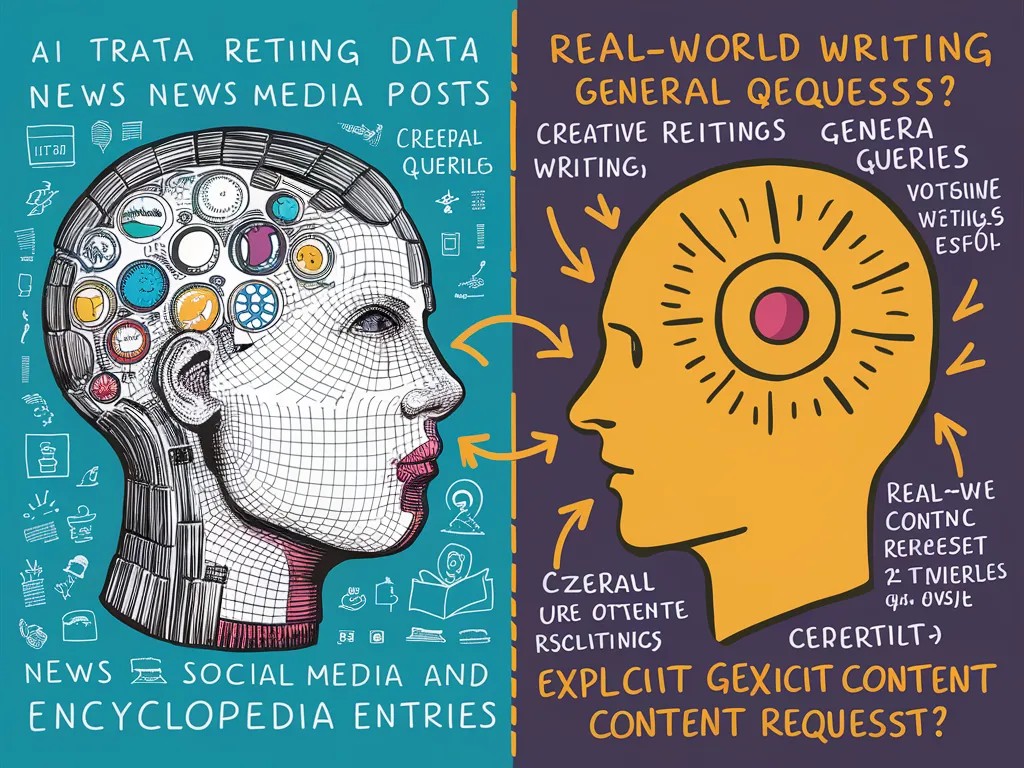
Imaginez que vous entraîniez un assistant IA en lui faisant lire des milliers d’articles d’actualité, puis que vous réalisiez que les gens l’utilisent principalement pour écrire des histoires fictives et poser des questions générales. C’est exactement le décalage surprenant révélé par une étude récente sur les données d’entraînement de ChatGPT.
Un fossé entre théorie et pratique
Les chercheurs ont examiné les données Web utilisées pour former les grands modèles de langage comme ChatGPT, ainsi que les journaux d’utilisation réelle. Ils ont découvert que :
- Les sites d’actualité représentent près de 40% des données d’entraînement, mais moins de 1% des requêtes réelles.
- Plus de 30% des interactions impliquent de l’écriture créative et des jeux de rôle, rarement présents dans les données.
- Les demandes de contenu sexuel sont fréquentes malgré la rareté de ce contenu dans l’entraînement.
Si les données utilisées pour former ces modèles ne reflètent pas leurs cas d’utilisation réels, comment pouvons-nous espérer qu’ils fonctionnent de manière optimale dans des scénarios réels ?
L’épineuse question du consentement
Un autre défi émerge : de plus en plus de sites Web restreignent l’exploration de leur contenu pour la formation de l’IA via des fichiers robots.txt. En un an, le pourcentage de contenu bloqué a augmenté de plus de 500% dans certains corpus clés.
De plus, de nombreux sites ont des instructions contradictoires entre leurs fichiers robots.txt et leurs conditions d’utilisation, rendant floues les règles d’utilisation des données. Ce manque de clarté complique la tâche des développeurs d’IA éthiques.
Que signifie cette étude pour l’avenir de l’IA ?
Ces résultats soulèvent des questions fondamentales sur les pratiques actuelles de collecte et d’utilisation des données pour former l’IA :
- Comment mieux aligner les données d’entraînement avec les cas d’utilisation réels ?
- Faut-il intégrer plus de contenu créatif et moins d’actualités ?
- Comment gérer les demandes de contenu sensible ou explicite ?
- Comment s’adapter à l’évolution des préférences de consentement des sites Web ?
Trouver le bon équilibre entre le respect de la vie privée, l’éthique et la performance sera crucial pour le développement futur de l’IA. Cette étude fascinante n’est que la première étape pour comprendre et résoudre le décalage entre la théorie et la pratique dans le domaine de l’IA.





